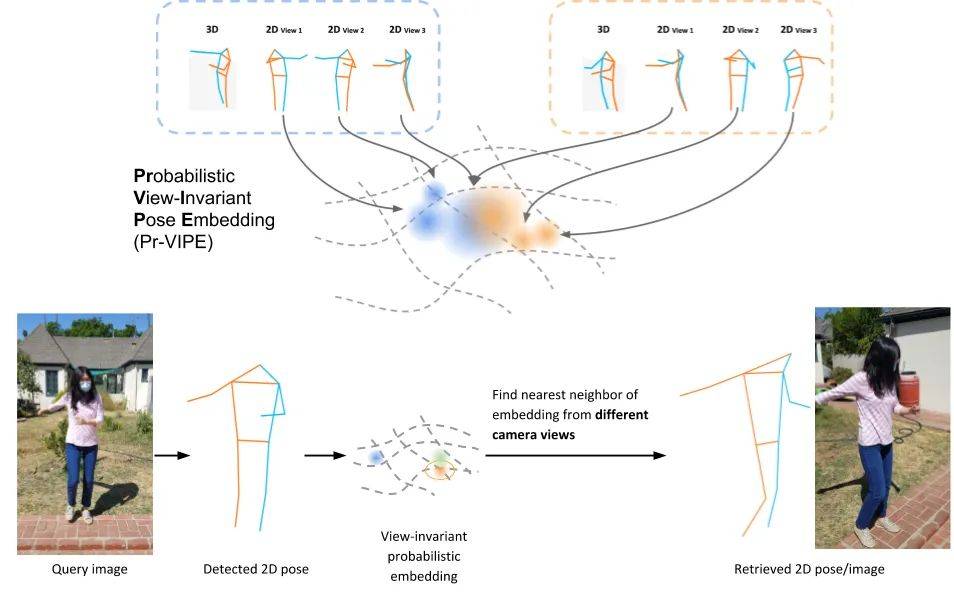
文 / Jennifer J. Sun 学生研究员和 Ting Liu 高级软件工程师,Google Research
全身手势控制 https://blog.google/technology/ai/move-mirror-you-move-and-80000-images-move-you/ View-Invariant Probabilistic Embedding for Human Pose https://arxiv.org/abs/1912.01001这种能力可以用于实现姿态检索、动作识别、动作视频同步等任务。与直接将 2D 姿态关键点映射到 3D 姿态关键点的 现有模型相比,Pr-VIPE 嵌入向量空间的特点包括 :
(1) 视角不变性,
(2) 为捕获 2D 输入模糊性引入概率性,
(3) 在训练或推理中无需相机参数。
现有模型 https://openaccess.thecvf.com/content_ICCV_2017/papers/Martinez_A_Simple_yet_ICCV_2017_paper.pdf经过实验室内设置数据的训练,只要有一个良好的 2D 姿态估计器(如 PersonLab、 BlazePose 等),模型即可开箱即用地处理自然场景中的图像。该模型很简单,嵌入向量紧凑,可以使用 15 个 CPU 进行训练(约 1 天内完成)。我们已经在 GitHub仓库上发布了代码。
Pr-VIPE 可以直接应用于从不同角度对齐视频
GitHub https://github.com/google-research/google-research/tree/master/poemPr-VIPE
Pr-VIPE 的输入是一组 2D 关键点,来自任何产生至少 13 个身体关键点的 2D 姿态估计器,输出是姿态嵌入向量的均值和方差。2D 姿态的嵌入向量之间的距离与其在绝对 3D 姿态空间中的相似度相关。我们的方法基于两个观察结果:
随着视角的变化,相同的 3D 姿态在 2D 中可能看起来有很大不同;
相同的 2D 姿态可以投射自不同的 3D 姿态。第一个观察结果引出了对视角不变性的需求。为此,我们定义了 匹配概率(Matching probability),即从相同或相似的 3D 姿态投射出不同 2D 姿态的概率。Pr-VIPE 预测的匹配姿态对的匹配概率高于不匹配姿态对。
为了解决第二个观察结果,Pr-VIPE 利用了一个基于概率的嵌入向量公式。由于许多 3D 姿态可以投射到相同或相似的 2D 姿态,因此模型输入表现出固有的模糊性,难以在嵌入向量空间中准确的捕获点对点的映射关系。因此,我们通过概率性映射将 2D 姿态映射到嵌入向量分布,用方差表示输入 2D 姿态的不确定性。例如,在下图中,左侧 3D 姿态的第三个 2D 视角类似于右侧不同 3D 姿态的第一个 2D 视角,因此将它们映射到嵌入空间中相似的位置时方差较大。
视角不变性
训练过程中,我们使用两个来源的 2D 姿态:真实 3D 姿态的多视角图像和投影。从一个批次中选择三组 2D 姿态(锚点、正样例、负样例),其中锚点和正样例是同一 3D 姿态的两个不同投影,负样例是不匹配的 3D 姿态的投影。然后,Pr-VIPE 根据其嵌入向量估算 2D 姿态对的匹配概率。
在训练过程中,我们最小化正样例对之间的嵌入向量距离,通过正样例对损失将正样例对的匹配概率逼近 1。在这个过程中,我们一方面最小化正例样本对在空间中的距离,另一方面同时通过使用 三元组比率损失(Triplet Ratio Loss) 使正样例对匹配概率和负样例对的匹配概率之比最大来确保负样本对之间匹配概率最小。
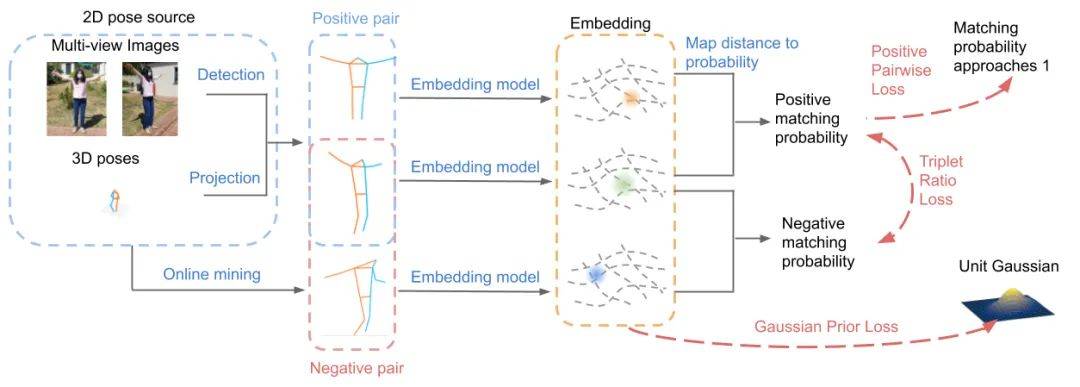
Pr-VIPE 模型概览:在训练过程中,我们应用了三种损失(三元组比率损失、正样例对损失和在嵌入向量上应用单位先验高斯的先验损失)。在推理过程中,模型将输入的 2D 姿态映射到一个概率性视角不变的嵌入向量
概率性嵌入向量
Pr-VIPE 使用基于采样的方法将 2D 姿态作为多变量高斯分布映射为概率性嵌入向量,以计算两个分布之间的相似度得分。在训练过程中,我们使用高斯先验损失对预测分布进行正则化。
评估
我们提出了一种新的跨视角姿态检索基准,以评估嵌入向量的视角不变性。给定单眼姿态图像,跨视角检索的目的是在不使用相机参数的情况下从不同视角检索出相同的姿态。
结果表明,在两个评估数据集(Human3.6M、MPI-INF-3DHP)中,与基线方法相比,Pr-VIPE 跨视角检索姿态的准确率更高。
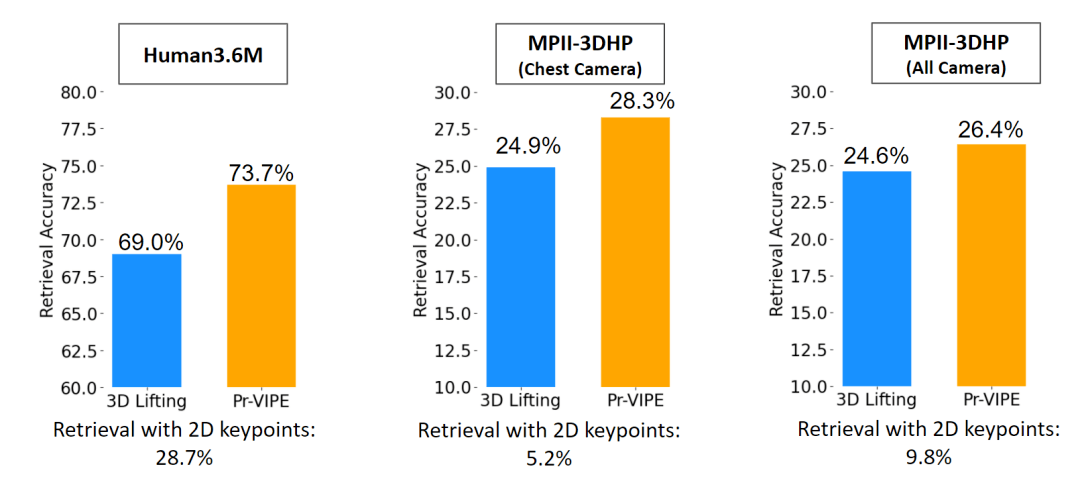
相对于基线方法(3D 姿态估计),Pr-VIPE 可以更准确地在不同视角中检索姿态
常见的 3D 姿态估计方法(如上面用于比较的简单基线、SemGCN 和 EpipolarPose 等),以相机坐标预测 3D 姿态,不直接具有视角不变性。因此,使用估计的 3D 姿态进行检索需要每个查询-索引对之间的刚性对齐,由于需要奇异值分解 (SVD),计算成本很高。相比之下,Pr-VIPE 嵌入向量可以直接用于欧氏空间的距离计算,而无需任何后处理。
应用
视角不变的姿态嵌入向量可以应用于许多与图像和视频相关的任务。下面,我们将展示在不使用相机参数的情况下将 Pr-VIPE 应用于自然场景图像的跨视角检索:

使用 Pr-VIPE 嵌入检测到的 2D 姿态,我们无需使用相机参数即可从不同的视角中检索自然场景图像。使用查询图像(上行),我们从不同的相机视角中搜索匹配的姿态,展示最近邻检索(下行)。这让我们能更轻松地在相机视角之间搜索匹配的姿态
同样的 Pr-VIPE 模型也可用于视频对齐。为此,我们在一个小的时间窗口内堆叠 Pr-VIPE 嵌入向量,并使用动态时间规整 (Dynamic Time Warping) 算法对齐视频对。

手动视频对齐既困难又耗时。在此,Pr-VIPE 用于从不同视角自动对齐重复动作的视频
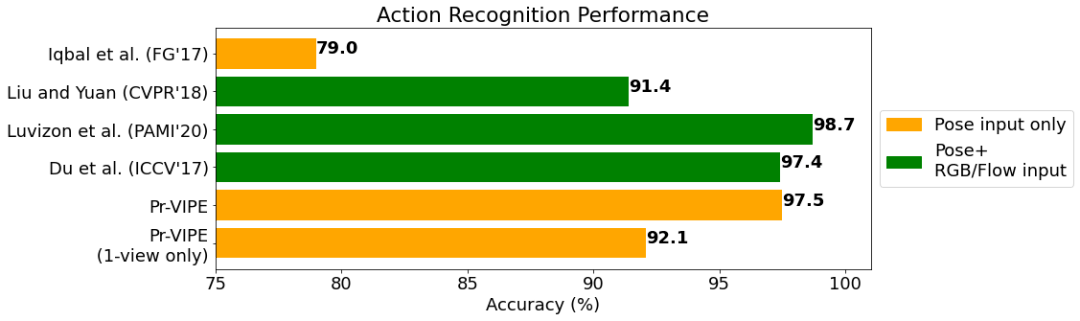
结论
致谢
特别感谢 Jiaping Zhao、Liang-Chieh Chen、Long Zhao(罗格斯大学)、Liangzhe Yuan、Yuxiao Wang、Florian Schroff、Hartwig Adam 和 Mobile Vision 团队的出色合作与支持。
查看 GitHub